When designing a study, you need to justify the sample size you aim to collect. If one of your goals is to observe a p-values lower than the alpha level you decided upon (e.g., 0.05), one justification for the sample size can be a power analysis. A power analysis tells you the probability of observing a statistically significant effect, based on a specific sample size, alpha level, and true effect size. At our department, people who use power as a sample size justification need to aim for 90% power if they want to get money from the department to collect data.
A power analysis is performed based on the
effect size you expect to observe. When you expect an effect with a Cohen’s d
of 0.5 in an independent two-tailed t-test,
and you use an alpha level of 0.05, you will have 90% power with 86
participants in each group. What this means, is that only 10% of the
distribution of effects sizes you can expect when d = 0.5 and n = 86 falls
below the critical value required to get a p < 0.05 in an independent
t-test.
In the figure below, the power analysis is
visualized by plotting the distribution of Cohen’s d given 86 participants per
group when the true effect size is 0 (or the null-hypothesis is true), and when
d = 0.5. The blue area is the Type 2 error rate (the probability of not finding
p < α, when there is a true effect).
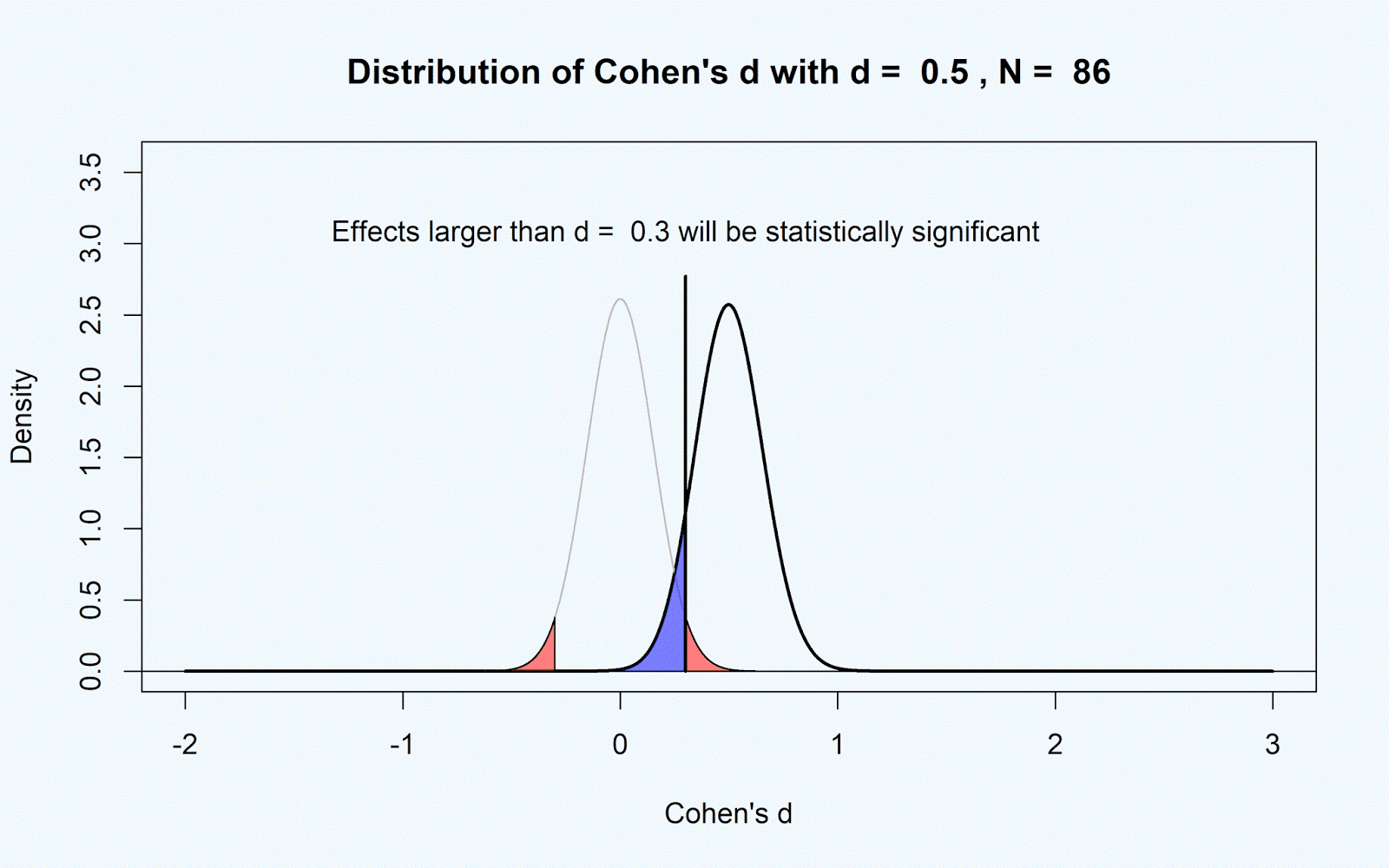
You’ve probably seen such graphs before
(indeed, G*power, widely used power analysis software, provides these graphs as
output). The only thing I have done is to transform the t-value distribution that is commonly used in these graphs, and
calculated the distribution for Cohen’s d. This is a straightforward
transformation, but instead of presenting the critical t-value the figure provides the critical d-value. I think people
find it easier to interpret d than t. Only t-tests which yield a t ≥ 1.974, or a d ≥ 0.30, will be statistically
significant. All effects smaller than d = 0.30 will never be statistically significant with 86 participants in each condition.
If you design a study where results will be
analyzed with an independent two-tailed t-test
with α = 0.05, the smallest true effect you can statistically detect is
determined exclusively by the sample size. The (unknown) true effect size only
determines how far to the right the distribution of d-values lies, and thus,
which percentage of effect sizes will be larger than the smallest effect size
of interest (and will be statistically significant – or the statistical power).
I think it is reasonable to assume that if
you decide to collect data for a study where you plan to perform a null-hypothesis significance test, you are not interested in effect sizes that will never be
statistically significant. If you design a study that has 90% power for a
medium effect of d = 0.5, the sample size you decide to use means effects smaller than d = 0.3 will never be
statistically significant. We can use this fact to infer what your smallest effect size of interest, or
SESOI (Lakens, 2014), will be. Unless you state otherwise, we can assume your SESOI is d
= 0.3, and any effects smaller than this effect size are considered too small
to be interesting. Obviously, you are free to explicitly state any effect
smaller than d = 0.5 or d = 0.4 is already too small to matter for theoretical
or practical purposes. But without such an explicit statement about what your
SESOI is, we can infer it from your power analysis.
This is useful. Researchers who use
null-hypothesis significance testing often only specify the effect they expect
when the null is true (d = 0), but not the smallest effect size that should
still be considered support for their theory when there is a true effect. This leads to a psychological
science that is unfalsifiable (Morey & Lakens,
under review).
Alternative approaches to determining what the smallest effect size of interest
is have recently been suggested. For example, Simonsohn (2015) suggested to set the smallest effect size of interest to 33% of the
effect size in the original study could detect. For example, if an original study used 20 participants per group, the smallest effect size of interest would be d = 0.49 (which is the effect size they had 33% power to detect with n = 20).
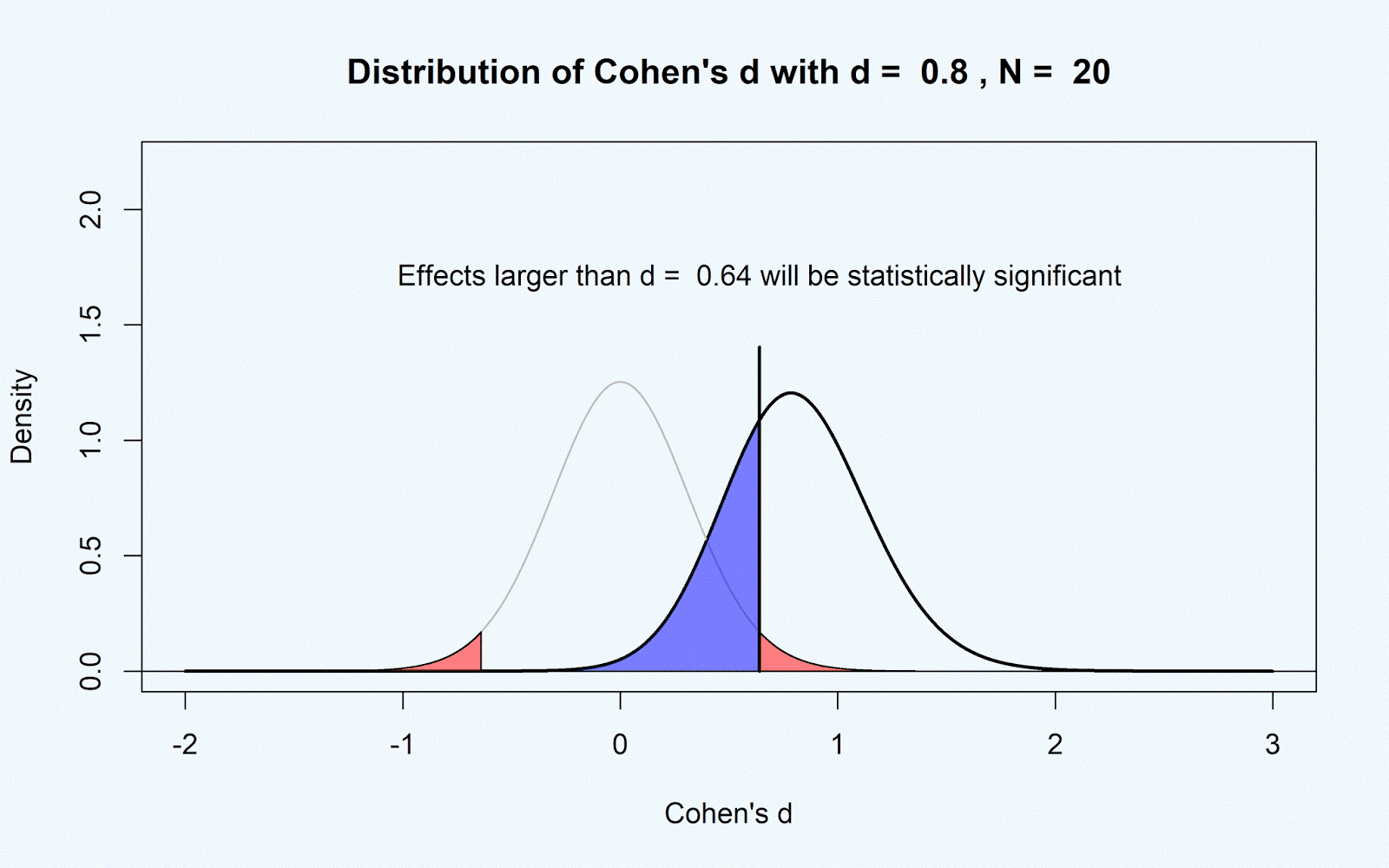
Let’s assume the original study used a sample size of n = 20 per group. The figure below shows that an observed effect size of d
= 0.8 would be statistically significant (d = 0.8 lies to the right of the
critical d-value), but that the critical d-value is d = 0.64. That means that
effects smaller than d = 0.64 would never be statistically significant in a
study with 20 participants per group in a between-subjects design. I think it makes more sense to assume the
smallest effect size of interest for researchers who design a study with n = 20
is d = 0.64, rather than d = 0.49.
The figures can be produced by a new Shiny app I created (the Shiny app also plots power curves and the p-value
distribution [they are not all visible on Shinyapps.org, but you can try HERE as long as bandwidth lasts, or just grab the code and app from GitHub] – I might discuss these figures in a future blog post). If you
have designed your next study, check the critical d-value to make sure that the
smallest effect size you care about, isn’t smaller than the critical effect
size you can actually detect. If you think smaller effects are interesting, but
you don’t have the resources, specify your SESOI explicitly in your article. You
can also use this specified smallest effect size of interest in an equivalence
test to statistically reject any effect large enough that you deem it
worthwhile (Lakens, 2017), which will help interpreting t-tests
where p > α. In
short, we really need to start specifying the effects we expect under the
alternative model, and if you don’t know where to start, your power analysis
might have been implicitly telling you what your smallest effect size of
interest is.
References
Lakens, D. (2014).
Performing high-powered studies efficiently with sequential analyses:
Sequential analyses. European Journal of Social Psychology, 44(7),
701–710. https://doi.org/10.1002/ejsp.2023
Lakens, D. (2017). Equivalence tests: A practical primer for t-tests, correlations, and meta-analyses. Social Psychological and Personality Science. https://doi.org/10.1177/1948550617697177
Morey, R. D., & Lakens, D. (under review). Why most of psychology is statistically unfalsifiable.
Simonsohn, U. (2015). Small Telescopes Detectability and the Evaluation of Replication Results. Psychological Science, 26(5), 559–569. https://doi.org/10.1177/0956797614567341
If experimental psychologists are basing their sample size requirements on the effect size they expect to observe, then they are making a mistake, because, for one thing, their experiment will be underpowered to detect a smaller effect size that they would still consider scientifically of interest. Sample size planning should always be based on the smallest effect size of interest.
ReplyDeleteThat's what I was thinking - the d = 0.3, i.e. what you call the smallest effect size of interest, is just the sample effect size, whereas the d = 0.5 you based the power calculation on is a postulated population effect size. If you have a smallest effect size of interest, wouldn't you want to treat it as a postulated population effect size and base your power computation on that?
DeleteIncidentally, your departmental policy sounds interesting (swing for 90% power). Do you have any worked out examples, i.e., of your colleagues identifying the effect size that they're investigating etc.?
Hi - current practice in power analysis is not very state of the art in psychology, and the problem is, smallest effect sizes of interest do not exist, are almost never used or specified. That's why I wrote this post - to bootstrap a SESOI, building from a practice people use (power analysis).
DeleteWe've had this practice of 90% power for about 2 years. I could give examples - very often people in our group specify a SESOI, or they look at a pilot study, and then use a more conservative estimate in a power analysis. If there is large uncertainty, we recommend sequential analyses.
Jan, although your last paragraph was presumably aimed at Daniel, rather than me, when applying for funding, I always base my proposed sample size on having 90% power to detect the smallest effect size of interest. This usually winds up giving me 99% power or more to detect the hypothesized true effect size.
DeleteJT - it's good you don't work at our department! Our ethics department would not be easily convinced by designing studies with 99% power - it's wasteful, and our resources can be spent more efficiently! You should really do sequential analyses (see Lakens, 2014, for an introduction (you are anonymous, so I don't know what you know about stats, but if you've never learned about sequential analyses, you should!).
DeleteDaniel, I'm a biostatistician, but I occasionally consult for social scientists. I disagree that 99% power is inefficient. We are interested not just in detecting an effect, but in obtaining a reasonably precise estimate of the effect size. The flip side of high power is narrow confidence intervals.
DeleteAs to sequential analysis, I agree that in many psych experiments the approach is useful. However, sequential analysis would not be practical in most studies I've been involved with. For example, if we need patients to be under treatment for three months, then, for many logistical reasons as well as financial ones, we really need the study to terminate after three months.
Should you ever run out of ideas for blog posts, I think one where you detail how you or your collaborators arrived at an effect size or SESOI would make for interesting reading. My sense is that power analyses are often based on canned effect sizes with little regard to the specifics of the study (theory and design), so it would be useful to see some more sophisticated approaches to specifying ESs.
DeleteHi Daniël! Interesting post. Just a detail: I think Simonsohn (2015) did not suggest to set the smallest effect size of interest to 33% of the effect size in the original study, as you write. He suggested to set the smallest effect size of interest so that the original experiment had 33% power to reject the null if this ES was true. This smallest ES of interest thus does not depend on the found effect size of the original study: it only depends on the sample size. For instance, for n=20 per cell in a two cells design, the effect size would be d=0.5, because this gives 33% power. Your approach is that the smallest ES is the effect size that gives 50% power in the original study. It makes a difference, but I think your approach is, in the end, quite close to Simonsohn's approach.
ReplyDeleteThanks! Changed (and I knew that - last minute addition I didn't think through! Thanks for correcting me!).
DeleteI think there is still a typo (or words missing) in that passage: "Simonsohn (2015) suggested to set the smallest effect size of interest to 33% of the effect size in the original study could detect."
DeleteI find this equivocating between observed ES and population ES. This is very common in psych, and it would really help if you labelled which you have in mind whenever used. Cohen had a subscript s for the observed ES. (I use difference for the observed, and discrepancy for the parametric effect size).
ReplyDeleteTo take the simple one-sample test of a Normal mean : Ho: mu< 0 vs H1: mu > 0, the cut-off for rejection at the 025 level is a sample mean M of 1.96SE. Are you saying the pop effect size of interest is this cut-off, 1.96 SE? That would be to take, as the pop ES of interest, one against which the test has 50% power. I'm not saying that would be bad, I'm just trying to figure out your equivocal use of effect size.
Since you asked about where it's equivocal, between pop ES and sample ES, here's one: you say "true effect size is 0 (or the null-hypothesis is true), and when d = 0.5."
ReplyDeleteHere d = .5 appears to speak of the pop ES. On your graph it's the observed.
Another: Your first figure shows d = .5 & also that d = .3, the first I take it is a pop, the second a sample.
A separate issue I have with using these standardized pop d's is that it seems you're allowed to do the analysis without knowing the standard deviation. Is that so?
I am always searching online for articles that can help me. There is obviously a lot to know about this.
ReplyDeletegclub
gclub casino
gclub
Dear Daniel,
ReplyDeleteThanks for sharing your thoughts. Doing power analysis using effect size, as its metric, does not really alleviate the problem you're thoughtfully raising, namely finding the smallest effect of interest. Because effect size is a simple transformation of other summary statistics (e.g., test statistics). As such, one can simply convert a critical test-statistic value to a corresponding critical effect size value. Such context-free, hypothesis-based view of power-analysis is both old and impractical. Plotting power against effect sizes is useful in conveying the message that the expression "Power of the test = some number" is basically not noteworthy. At a larger level, these revelations are instead important in moving the social and behavioral research toward thinking in terms of Bayesian estimation of effect sizes. If you're interested in frequentist power-analysis, much better ways of doing such power analyses is available via loss functions (frequentist decision theoretic approaches). The traditional power-analytic approach you discuss here has criticisms that take more space, but in short other type of errors than type I and type II are to be involved in the power analysis process.
Hi, loss functions are what we need to work towards. But our field has no clue where to start - this post shows how we can bootstrap a SESOI, and in 10 years, maybe end up with loss functions. If you can give me 20 examples of adequately developed loss functions in psychology, that would be great. If you can't (and you can't) it proves the point of my post.
DeleteDear Daniel,
ReplyDeleteThat's what good methodologists such as yourself are for, right! Promoting good stuff! Ken Kelly, for example, has implemented loss functions for use in a wide range of power-analytic situations in his package. I'm mathematical statistician and really understand some of the limitations in human research. I also mentioned in passing that other types of error for small-sized research such as the ones in psychology are to be seriously heeded when doing power-analysis in the traditional sense. I believe Andrew Gelman has a math-free paper on this topic which is publicly available. Anyway, the point was that, a "Cohen's d" sampling density is simply a "location-scale" version of t-distribution. You make good comments that prepare your colleagues to adopt a bayesian approach to the estimation of the parameters of their interest. Best of luck with your work. Keep it up!
I don't see a lot of benefit of incorporating prior information in inferences in the next decades, given the current state of knowledge. Can you point me to KEn Kelley's loss functions? I could not find any information in MBESS or on his website, but it is a topic I actively plan to work on in the next years so I'd appreciate any info you can share.
DeleteDear Daniel,
ReplyDeleteThank you for your post! I'm a beginner trying to understand power analysis and equivalence test/SESOI calculation. One of your assumptions is that your data has a normal distribution. What it would be your approach if not?
It's the same idea, just different calculations.
ReplyDeleteThanks Daniel! Do you have any recomendations to test equivalence in non-normal data?
ReplyDeletethanks for sharing the nice idea.
ReplyDeleteหนังผีฝรั่ง
Re: "you are not interested in effect sizes that will never be statistically significant"
ReplyDeleteI would add "...within a time frame that is credible" i.e. findings are most likely to be significant while power is low, well before the "estimated" duration, but these are less likely to reproduce.
Anyway, I had a similar thought, I think. I opted to address uncertainty about the effect size by showing a range of effect sizes. I think ranges are more intuitive than single numbers, esp. when the likely effect size is hard to estimate. The idea is: I first see some reasonable proposal as to how long and what I can detect, then I adjust duration until the range feels achievable given what is being tested. In online analytics, it works, because duration can be extended indefinitely, but usually quick decision are needed. If my duration fixed, I can gauge by best case scenario.
Here's the reverse sample size / effect size calculator I came up with: http://vladmalik.com/abstats
On top of visualizing power, I also wanted to see the impact on false positive rate in case my hypothesis is wrong e.g., I could gauge if the results I am seeing are within the range predicted by pure chance.
I've no formal training in stats, so I was always curious if my approach to this has merit in other real-life scenarios. Glad to see you're doing something somewhat similar. Would love to hear your thoughts too.
This comment has been removed by a blog administrator.
ReplyDelete